

How Rootclaim Works
Synopsis
Rootclaim outperforms human reasoning by using probability theory to correct for the biases and flaws of human intuition. Its conclusions represent the best available understanding of the complexity and uncertainty in our world.
The problem is well-known: An important event occurs, lots of evidence is available, yet different parties claim completely opposing conclusions from the same evidence. A public struggle ensues regarding the narrative, and there is no clear way to determine who’s correct. Examples: What happened to Malaysia Airlines flight 370? and Who carried out the 2013 chemical attack in Ghouta?
Why does this happen? How can intelligent people reach opposing conclusions from the same data? The human brain is simply not equipped to deal with complex situations, where there is an abundance of evidence that supports contradictory conclusions.
The main human flaws causing this failure are:
- Filtering of evidence - coming to a conclusion without seeing the full scope of the evidence, or intentionally cherry-picking due to personal biases and interests.
- Reliance on gut feelings and conventional wisdom to assess likelihoods, instead of using verified statistics.
- Ignoring the initial plausibility of a hypothesis - concluding that a certain explanation is correct because the evidence seems to fit, without considering the likelihood of the explanation itself.
- Weak intuition for compounded probabilities: Even when correctly analyzing each piece of evidence individually, the human brain is unable to intuitively assess the combined effect of all the evidence.
- Overlooking dependencies between multiple events, where the occurrence of one affects the probability of another to occur, causing people to overweight the evidence.
Rootclaim corrects these flaws using probability theory, the mathematical branch that deals with human uncertainty, allowing us to assess likelihoods in complex situations far better than human intuition. The Rootclaim method still heavily relies on human inputs in those arenas where humans are more flexible and creative.
A Rootclaim analysis uses the following methodology:
- Gather all likely hypotheses. It’s important that this is performed by humans, since a machine cannot find hypotheses by itself, and additional hypotheses are often crafted that can fit the evidence better than the official explanations offered by either side. People also need to describe each hypothesis fairly and accurately in order to distill the essence of each claim, whereas automated processes would only regurgitate that which had already been written.
- Assess the initial likelihoods (prior probabilities) of each hypothesis. This is important since a hypothesis that starts out already unlikely (e.g., “Aliens did it!”) would need a lot more evidence to become likely. If a hypothesis is already reasonable, one would need less evidence to back it up.
- Gather all the available evidence, without cherry picking. Evidence is explicitly listed, so any one can easily point out important missing evidence.
- Sort information into evidence groups to account for dependencies. This prevents overweighting the evidence and inconsistencies when explaining multiple pieces of evidence that are all a consequence of one common cause.
- Quantify how each group of evidence affects the likelihood of each hypothesis.
- Once all elements have been quantified, proven mathematical formulas calculate the final likelihoods of each hypothesis.
Deficiencies of human analysis
Rootclaim provides a platform for analysis that is far superior to human reasoning. We do this by identifying the main flaws in human reasoning, and counteracting them with proven mathematical models and set procedures.
The Rootclaim method is thus a hybrid process in which people contribute to those areas where the human brain works reasonably well, and mathematical models are used where the human brain cannot be trusted. Specifically, people are involved in the following processes:
- Finding reasonable hypotheses
- Collecting relevant evidence
- Comparing details to similar events from the past and referencing relevant statistics
- Detecting dependencies between pieces of evidence
This work is performed by our team, with the help of the crowd. A key component of the Rootclaim platform is that the inputs and results of this process are displayed openly and clearly: anyone can point out mistakes and suggest improvements (see how). This is crucial to avoid common human weaknesses such as cherry-picking, tunnel vision, and cognitive dissonance.
When it comes to integrating multiple pieces of information, the human brain collapses under the weight of the data and generates complete nonsense () - which is why you constantly see intelligent people reaching opposing conclusions even when drawing from the same pool of data. Therefore, Rootclaim uses proven mathematical models from probability theory to integrate all these inputs into a calculated likelihood of each proposed hypothesis.
It is important to understand that this model is well-known and mathematically proven, meaning that the calculated result is the only possible conclusion, given the human inputs provided to it.
Probability theory
Probability theory allows us to leverage the facts that we know in order to overcome our mistaken intuition. Let’s start by understanding why probability theory offers the best solution to reduce uncertainty and reach more accurate conclusions in complex situations. Though actually, since probability theory is a branch of mathematics, we need to first understand what mathematics is. This is a tricky question with no accepted answer, but the following is close enough.
Defining math
Mathematics is an extension of human intuition, by the rigorous application of intuitive rules to intuitive concepts.
The intuitive concepts are known as axioms - a set of statements accepted to be true, usually because everyone intuitively “feels” they are true. They do not require proof. For example: “There is only one straight line that contains two different points”.
The intuitive rules are commonly referred to as logic, and include the basic inference tools that all human brains share. For example: if A implies B, and we find that A is true, then we know that B is also true (known as “modus ponens”). When applying these rules, over and over, on the axioms, very advanced conclusions may eventually be reached.
When the axioms describe truths about the world (as perceived by our senses), then mathematics provides a much deeper understanding of the world, and allows us to make deductions and predictions that our brains would not be able to do otherwise - and this is where mathematics creates enormous value. For example, since the axioms of geometry are similar to objects that we perceive with our senses (points, lines, planes, etc.), geometry provides us strong tools to understand the world around us - e.g. estimating the volume of a cone, something that no one could find by intuition alone, without math.
Understanding probability theory
Now we can return to probability theory. Probability theory defines a set of axioms relating to how the human brain perceives uncertainty. In other words, it is the math of uncertainty.
The axioms of probability theory are called Kolmogorov axioms, and include trivial statements such as: if a set of events are mutually exclusive (one cannot happen if another occurred), then the probability of at least one of them happening is equal to the sum of the probabilities of each.
Since these axioms match up with our intuitive understanding of “probability”, the resulting theorems built on them allow us to make advanced probabilistic inferences. For example, this diagram shows a Bayesian network capable of inferring the probability of various diseases, given the patient’s symptoms - something that no human can calculate intuitively.
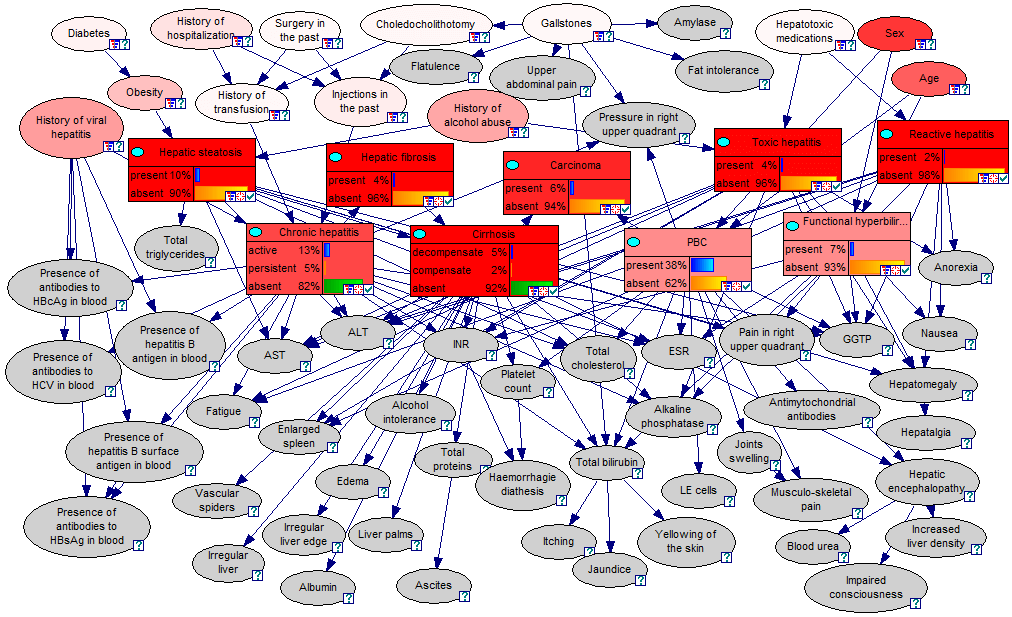
To summarize, if we accept that the Kolmogorov axioms provide a true representation of our intuition for probability and uncertainty, then probability theory provides us a method to estimate probabilities and reduce uncertainties in complex situations, in a way that is mathematically proven to be correct, and is therefore superior to human intuition.
Rootclaim developed a process for taking a complex question and analyzing it in a way that a probabilistic model could be effectively applied to it. How is this done?
Identifying the challenge
Every event in our world is unique. It is one of a kind. For example, suppose tomorrow there is a basketball match between the USA and Argentina, and we want to estimate the probability that Argentina will win. This game, with the exact line-ups, court, referees, audience, players’ health, etc. will never repeat. Each game is unique, and is affected by endless parameters that are unique to that event.
It seems very different than throwing a die and predicting the probability of landing on each side. But that’s only an illusion, because each throw of a die is also affected by endless parameters: initial momentum, height, surface composition, etc..
The difference is that people designed dice so that these parameters would be well beyond the capabilities of the human brain to analyze. Our ignorance regarding a set of dice is constant among throws, and is equal for all sides. We, therefore, view all throws as identical events, and are able to easily analyze them using statistics.
Thus, measuring probability is subjective: it is not a property of the event, but of the person viewing the event - it is a measure of that particular person’s level of ignorance.
Returning to the dice example: The probability of rolling any given number is ⅙ only if the observer is ignorant to the physical parameters and their effects. But what if someone used a computer vision system to track the die’s position and velocity immediately after the throw? That information could allow predicting the outcome more than 1 in 6 times.
If you were to use this tracking system to continually refine your assessment of the probabilities as the die flies through the air, the system would provide fine-tuned outputs at each moment. As more information is gathered (such as the exact position as the die slows down and the features of the surface the die is on), the greater the certainty regarding the outcome. So not only is probability dependent on the observer, it can also vary over time for the same observer.
So how would we analyze the basketball game? Our brain has the capacity to do extensive pattern matching. We can detect elements that repeat over different events, and represent those patterns in our minds. We can then associate those patterns with different outcomes, and over time build a model that allows us to better predict the outcome in a new event.
For example, we can see that the haircut of the players has little effect on the outcome, but the injury of a significant player does have an effect. As we accumulate more information, more inputs, more statistical patterns from the past, and as we understand how these correlate with the results, we can make better predictions regarding the probability that a certain team will win.
Similarly, when we want to analyze a factual controversy such as who committed a particular murder, we collect the evidence of the case and based on that evidence, as well as our knowledge of past similar events, we try to estimate the likelihood of each suspect. Humans are pretty good at collecting evidence and statistics, thinking of new hypotheses, understanding what is relevant to the case at hand, and recognizing which past events are important to analyze and which are not. However, after we collect the information, humans do not reliably understand how the huge amounts of data affect the final outcome of the analysis. This is largely due to common flaws in human reasoning.
How to proceed
These weaknesses naturally discourage humans from using probabilistic reasoning. Instead, most people attempt to understand the world through logical deductions, which promise a more clear-cut, rule-based approach. We like to outline our reasoning using statements that gradually build to an inevitable conclusion, and we enjoy pointing out the logical fallacies in opposing claims.
Unfortunately, logic rarely works in the real world, as it does not handle uncertainty. When it comes to complex analyses there may be hundreds of premises and hidden assumptions, and each comes with some uncertainty. As that uncertainty accumulates, the reliability of the final conclusion drops rapidly. Read here for a deeper understanding of the limitations of logic.
Probability theory is the correct tool for such analyses because it gives us the mathematical tools to describe complex systems while tracking how uncertainty propagates within them.
Rootclaim is a method for mapping complex real-world problems into a probabilistic model. It breaks down large complex problems into many dozens of small problems, each within the capacity of the human brain to analyze. We then use proven mathematical models from probability theory to integrate the data together to calculate the likelihood of the possible conclusions, far better than human reasoning can.
The Rootclaim method
First, we identify an event that is controversial: there’s a difference of opinion about what happened. If the difference of opinion is not due to simple gaps in information or political interests, that means it is likely due to weaknesses in human reasoning. This is where Rootclaim offers a superior solution.
The Rootclaim process starts by assessing the initial likelihoods (prior probabilities) of the competing hypotheses. It then goes through all the evidence, analyzing how they affect each hypothesis. The likelihoods are updated accordingly at each step, until all relevant evidence is accounted for, and a conclusion is reached.
Let’s examine these components in detail.
Background
The first step sets the stage for the analysis. We identify the question that needs to be answered, focusing on the main point of contention. Next, we describe the background details. These are the undisputed facts of the case which will be used to assess the initial likelihoods of the hypotheses, and help evaluate the evidence.
Hypotheses
Next we identify the competing hypotheses - the best explanations currently offered for what happened. These would usually include the mainstream versions offered by the opposing sides: prosecution vs. defence, USA vs. Russia, etc. Sometimes additional hypotheses are crafted that could fit the evidence better than the official explanations offered by either side.
We begin quantifying the inputs by calculating the prior probability of each hypothesis. This is necessary because, if a hypothesis starts out already unlikely (e.g., “Aliens did it!”), one would need a lot more evidence to prove that it’s true. Conversely, if a hypothesis is already reasonable, one would need less evidence to back it up. Neglecting the prior probability is a common flaw in human reasoning, which Rootclaim avoids by explicitly requiring at as an input.
When assessing the prior probability, we use our understanding of the world to decide which attributes of the events are relevant. So, to return to our basketball example, hair cuts would not be relevant factors, while past matchups between these two teams and player health conditions are extremely relevant. Ideally, those definitions would be general enough so we can find enough past events with similar attributes that we can use to gather statistics (a few dozen events are normally enough for the accuracy levels expected here), but also specific enough so the statistics are relevant to the case at hand.
This requires focusing on a small number of attributes. This is why it’s important to choose attributes that have a strong effect on the hypotheses’ likelihoods.
Evidence
We now have the initial numbers, and can start updating them according to the evidence. First and foremost, all the evidence must be listed, without cherry picking. We make sure to include the main evidence points raised by both sides, and continue to receive feedback after publication, allowing the crowd to offer evidence that may have been missed.
Grouping and dependencies
Evidence in a Rootclaim analysis is grouped in a way that simplifies the analysis and improves readability as much as possible without significantly impacting accuracy.
One consideration in how to group evidence is dependencies: The evidence of the case are, by definition, dependent on the hypotheses. For example, if the suspect is guilty then all the guilt-related evidence become more likely: there’s a greater likelihood that he was at the crime scene, that he had a motive, and that he lied about his whereabouts. So once we encounter one of these pieces of evidence, we are more likely to encounter the others. However, sometimes evidence may additionally have dependencies given the hypotheses, meaning that we expect to encounter these pieces of evidence together even when considering just one of the hypotheses - in other words, there is some common cause other than the hypotheses.
For example, in a murder investigation, once there is one piece of evidence that a suspect was at the murder scene, we could expect additional evidence of his presence, even if he is innocent. We need to determine the likelihood that he would have been at the scene of the murder under both hypotheses, and thereby how it affects the likelihood of guilt. But finding additional evidence of his presence only solidifies our knowledge that he was there: it no longer has a significant effect on the likelihood that he is guilty.
Another factor is the process that generated the evidence in the first place. Each piece of evidence is a result of some search or investigation, which has some chance of producing this evidence, and that probability is different under different hypotheses. For example, the suspect providing the correct eye color of the victim in his confession has a relatively high likelihood if he is the murderer, and a lower likelihood if he’s an unrelated person providing a false confession. He could, of course, still guess the correct eye color even if he’s innocent.
So here the generating process is the interrogation of the suspect, and the evidence is which information he provided correctly. For each question he can provide an answer that is either correct or wrong, with correct answers being more likely if he is guilty. If he is innocent, a correct answer is less likely, depending on how hard it is to guess. So eye colors and hair colors are easy to guess, but the location of a particular scar is harder to guess.
A common mistake in human investigations is to filter only the matches, without considering them as part of a larger process generating large amounts of evidence, some of it matching and some of it not matching.
A judge presented only with the matching information could wrongly deduce that the suspect indeed knows a lot of details regarding the murder scene, which is very unlikely if he is innocent. However, it’s possible that when considering all the questions asked and all the wrong guesses given, then the distribution would be exactly as expected from an innocent person trying to guess details to please his interrogator. In such a case, it would be clear that he’s guessing the easy guesses at a frequency that is expected by chance (e.g. correctly guessing half the questions that have two equally likely answers). By examining all the evidence from the source together, including mismatches, or missing evidence, viewed as a unit, the significance of the evidence can be assessed more accurately.
It is interesting to note that if enough information is gathered here and we have a good reason to believe it wasn’t filtered and cherry picked, for example it’s all taken from a continuous recording from the interrogation, then the number of hits, misses, and their probabilities could provide together very strong evidence for one of the hypotheses - meaning that that exact distribution is extremely unlikely under all the other hypotheses.
Assessment
Once the evidence is grouped, each group is summarized to one or more conclusions, and assessed for its effect on the hypotheses.
If the evidence together points to a very clear conclusion, and doesn’t require advanced probabilistic inference to reach, then it is simply stated in the text field. For example, if the evidence overwhelmingly shows the suspect was at the scene of the crime there’s no need to examine each piece of forensic evidence by itself: fingerprints, DNA, footprints, etc. The evidence together is titled “the suspect was at the scene of the crime” and then we assess the probability of him being there under each hypothesis, innocent or guilty. There, of course, could be legitimate reasons for the suspect to be at the scene of the crime even if he was innocent.
In some cases the evidence is not conclusive. In that case, the evidence will be summarized without a definitive statement. Phrasing the evidence more generally as “lab results suggest that X was at the scene, but there were some indications of human error” allows each hypothesis to quantify the effect of that evidence.
After carefully phrasing the evidence (either conclusively or more generally), we estimate how it affects the hypothesis. We do this by assigning a factor to each hypothesis that is relevant to that evidence. This factor is known in probability theory as the odds ratio, and measures the likelihood of this evidence if the hypothesis is true vs. the likelihood of this evidence if the hypothesis is false. If the odds ratio is 1 then the evidence doesn’t really affect the hypothesis. If this ratio is higher than 1 (it’s more likely that this piece of evidence would exist if the hypothesis is true) then it increases the likelihood of that hypothesis, but if the ratio is lower than 1 it reduces the likelihood of that hypothesis. For example, a confession may increase the likelihood of guilt by 4x (e.g. if 60% of the guilty make such a confession, but only 15% of the innocent). Conversely, a cellphone call from a far location may modify the likelihood of guilt by 1/10x (because that points to the suspect not being near the murder scene, though he may have deliberately arranged for someone else to make the call).
Organization
The evidence groups are ordered and the effect of each one is estimated given all of the evidence contained in the previous groups. In most cases evidence groups are assessed independent of other groups. The analysis should strive to make them independent, but if that’s impossible, the evidence group will be assessed taking into account the preceding evidence groups only and not the subsequent ones. For example, let’s assume a first evidence group shows that a suspect was seen in a certain location and a second evidence group shows that the suspect’s fingerprints were found on the murder weapon which was found at that location. Then in the first evidence group we would compare the likelihood of the suspect being in that location if he’s guilty with the likelihood he was there if he’s innocent. But in the second evidence group we would compare the likelihoods after already assuming he was at the scene: the likelihoods he would touch the weapon given we already know he was there.This ensures that dependent events are assessed only once.
Evidence groups occasionally contain lower level groups of evidence, which themselves may contain more evidence and so forth. This creates an easy-to-read analysis where you can drill down whenever some part of the analysis is unclear. It also allows the analysis to start with the top-level view that can be published very quickly after the event occurs, and then expand as more evidence and feedback from the crowd comes in.
Confidence
An important feature in Rootclaim’s evidence analysis, which is often neglected in other approaches, is the ability to account for mistakes in the analysis itself. Evidence groups have an optional field stating the probability that there is a mistake in the analysis, meaning that the evidence may not affect the analysis the way we estimated. This is especially relevant in complex cases such as claiming the forensic importance of some evidence, where the forensic field is not that developed, we don’t have enough statistical history, or we are using the field in a way that is not often used. This prevents weaknesses in the analysis from over-influencing the final result.
This probability is treated as a cap on the maximal effect the evidence can have on any hypothesis. A confidence of 80% means a 20% probability (or 1 in 5) that the analysis is wrong, which will limit this evidence to have an effect between ⅕x and 5x. The reasoning behind this calculation is to always choose the most probable path to explain the evidence. For example, if a DNA match was found to a suspect, it will often be quantified as “1 in a billion probability of matching by chance” (i.e. a random person having all tested DNA markers). However, a much more likely possibility would be for a mistake in the lab (say 1 in 100). This is the more likely explanation under the “innocent” hypothesis, and its likelihood should therefore be reduced by 1/100, not 1 billionth.
As a side note, a more accurate calculation should take into account both options, but in the interest of readability we choose to use only the most likely option, without a major effect on accuracy.
Additional examples:
Factor ×10, confidence 100% => ×10
Factor ×10, confidence 95% => ×10
Factor ×10, confidence 50% => ×2 (the more likely path is that there was a mistake)
Factor ×1/10, confidence 50% => ×1/2 (the more likely path is that there was a mistake)
Factor ×100, confidence 90% => ×10 (the more likely path is that there was a mistake)
Factor ×1/20, confidence 90% => ×1/10 (the more likely path is that there was a mistake)
In this manner, we significantly limit the effect our own human faults can have on the accuracy of the analysis.
Calculation
After we have estimated the prior probability and assessed the effects of each evidence group on the hypotheses, it’s relatively simple to calculate the final likelihoods: we start with the prior probability of each hypothesis, multiply by the likelihood factor for each of the evidence groups, and then normalize to receive the final likelihoods.
As a simple example, imagine a case with only two hypotheses (suspect is guilty and suspect is innocent) and two evidence groups. Say the prior probability was 90% innocent vs 10% guilty, the first evidence group was 5x less likely under the “innocent” hypothesis, and the second evidence group was 3x more likely under the “guilty” hypothesis. In that case, the updated likelihood the suspect is innocent is 90% * .2 * 1 = 18% and the updated likelihood he is guilty is 10% * 1 * 3 = 30%. Normalized, these values give you the calculated conclusion of 37.5% innocent to 62.5% guilty. Here’s a graphic presentation of the same calculation:
| Innocent | Guilty | |
| Prior | 90% | 10% |
| Evidence 1 | 1/5x | 1x |
| Evidence 2 | 1x | 3x |
| Product subtotal | 18% | 30% |
| Normalized | 37.5% | 62.5% |
Using this methodology, Rootclaim blends human inputs with mathematical calculations in a way that maximises human reasoning and minimizes cognitive biases and mistakes.
Once again, this is a well-known and proven mathematical model, and if the first part (human inputs) was done well, the calculated conclusion will be accurate. See how past Rootclaim analyses withstood the test of time here.
We're automating Rootclaim! 🤖
Rootclaim's team is currently fully dedicated to teaching AI models the art of probabilistic inference, and will likely not be publishing new analyses in the meantime. If this effort is successful, we will be able to provide accurate and transparent analyses of every public controversy immediately as it happens - a service we think humanity desperately needs.